
Apache Spark is at present a standout amongst the most dynamic ventures in Hadoop ecosystem, and there’s been a lot of buildup about it in the past few months. In the most recent webinar from the Data Science Central webinar series, titled “Let Spark Fly: Advantages and Use Cases for Spark on Hadoop,” practical benefits for having full set of Spark Technologies available to your disposal are revealed.
Apache Spark is an execution platform that enables growth of computing workloads which Hadoop can deal with, while additionally tuning the performance of the big data framework.Apache Spark has various preferences over Hadoop’s MapReduce execution engine, in both pace with which it carries out batch processing jobs and the amount of computing workloads it can handle. Apache Spark also has the ability to execute batch processing between 10 to 100 times speedier than the MapReduce engine as indicated by Cloudera, primarily by decreasing the amount of writers and reads to disc.
Apache Spark is an execution platform that enables growth of computing workloads which Hadoop can deal with, while additionally tuning the performance of the big data framework.Apache Spark has various preferences over Hadoop’s MapReduce execution engine, in both pace with which it carries out batch processing jobs and the amount of computing workloads it can handle. Apache Spark also has the ability to execute batch processing between 10 to 100 times speedier than the MapReduce engine as indicated by Cloudera, primarily by decreasing the amount of writers and reads to disc.

What Spark really does really well is this idea of a Resilient Distributed Dataset (RDD), which permits you to transparently store data on memory and continue it to plate in the event that it’s required.The utilization of memory makes the framework and the execution engine truly quick.In a true test of Spark’s execution in cluster, Cloudera says, a vast Silicon Valley web organization saw a three times speed increases in the execution of porting a solitary MapReduce job implementing feature in a model training pipeline.
As the level of “memory to handling” rapidly develops, many individuals inside Hadoop gathering are coasting towards Apache Spark for quick, in-memory data transformation. In addition with YARN, they use Spark for machine learning and data science utilize the cases incorporated with distinctive workloads in the meantime.
As the level of “memory to handling” rapidly develops, many individuals inside Hadoop gathering are coasting towards Apache Spark for quick, in-memory data transformation. In addition with YARN, they use Spark for machine learning and data science utilize the cases incorporated with distinctive workloads in the meantime.
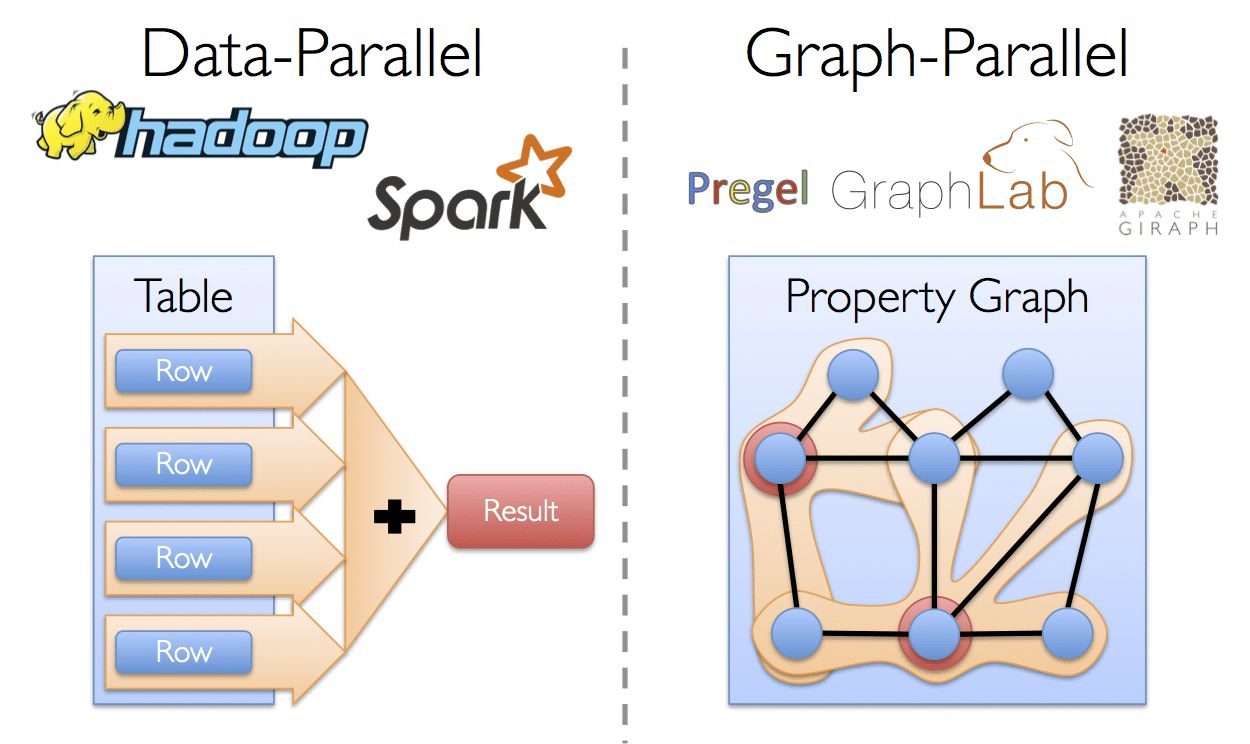
Apache Spark licenses information researchers to suitably and essentially actualize iterative figuring’scutting edge analytical operations, for e.g. clustering and preparations of datasets.
It is in the blink of an eye a top level Apache venture and is creating as a charming option to run some cautious information science workloads.
It gives three key value points to developers that make Spark the best decision for data analysis methods. It gives the alternative of in-memory computation for immense measure of diversified workloads. It likewise comes with the tool of disentangled programming model in Scala and machine learning libraries that tremendously simplifies programming and programming needs.
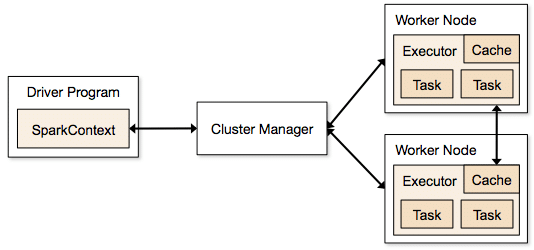
At its middle, Spark gives a general programming model that enables planners to create application by framing self-assertive administrators, for e.g., mappers, reducers, joins, groupings and channels. This structure makes it easy to express a wide group of calculations, including iterative machine learning, streaming, complex inquiries, and bunch.
Furthermore, Spark stays informed concerning the information that each of the administrators delivers, and empowers applications to dependably store this information in memory. This is the way to Spark’s execution, as it permits applications to keep away from immoderate circle of information transformation.
No comments:
Post a Comment