
For Hadoop to be installed there are some certain pre-requisites such as Supportive platforms like GNU/Linux or Win32 and softwares like Jawed and SSH must be installed and enabled; a proper environment is needed for the system to be installed. If your cluster does not come with all the requisites then you will have to download and install them by yourself which is not that difficult. You can download the latest Jaw version compatible with Hadoopfrom this link http://stackoverflow.com/questions/10268583/how-to-automate-download-and-installation-of-java-jdk-on-linux
Further Configuration of SSH access is needed to enable master/principal and secondary node to get access to the system and take over the slave nodes and handle local users and machines. Generate an SSH key, log in and run the command of key generation. The last step of this process is to check whether machine/machines are connected and working with the main user enabling the local host to permanently combine with other known hosts.
Then to install Hadoop you will need a Hadoop distribution which is available on Apache Download Mirrors (http://www.apache.org/dyn/closer.cgi/hadoop/common/). To make things lot easier you can install softwares like Ubunto-64 bit or MVPlayer
In Ubuntu you have an option of Downloading Hadoop by its latest release, choose to download a stable release, unpack the download and extract it.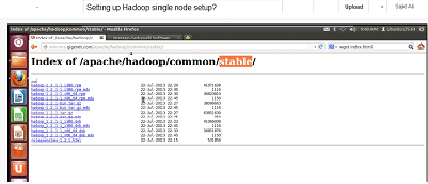
This will start the installation process and the next step of the installation will be configuration of your Jaw path. The step is simple as you just have to edit the pre defined perimeter of the path in the system and change it according to your user defined path.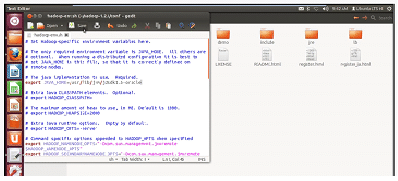
Edit the built in changeable location address according to your own Jaw address and save it.
Next step would be to add dedicated Hadoop system user to make the system operational. This step isn’t that much important but it will help keeping Hadoop segregated from other applications, user IDs and softwares.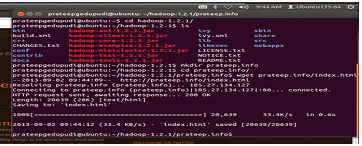
Now disabble IPv6 as it is necessary to unbind Hadoopbut if you are connected to a IPv6 network then there is no need to disable it.
The last step is to format and edit the nodes of Hadoop file system, which is only necessary if the system is not already in use. The process is performed by a simple command
Hadoop namenode-format
Now You can make sure whether the software is fully operational or not by giving a task to the system, hopefully this will work and you will have a smile on your face.
Hadoop can be stopped instantly by commands given below;
- Stop-dfs.sh
- Stop-yarn.sh
Hadoop has many web interfaces which are very much user firendly, available at these addresses;
- http://localhost50070
- http://localhost50090
This ends the whole process and now you can enjoy the ease of handling your big data conveniently and effectively, but no doubt you will have take Hadoop training which will improve your expertise and skill. I hope the whole process was easy to understand and helpful to the readers. With an ending note, I must add that Big data technologies are very imparitive to use and very heplful in managing data. Now online courses are provided, initiated by the need of data managing technolgies. Companies like Yahoo and Google(which is also the founder of Hadoop system) are among the big usres of the system and it is forecasted that in times to come around 80% of the world data will be managed by either Hadoop or other data manging softwares.
No comments:
Post a Comment